


Liever luisteren dan lezen? Dit artikel is ook beschikbaar in gesproken variant:
![]()
![]()
![]()
![]()
![]()
Nee, niet Morgan Freeman, maar Boet Schouwink. Boet is al 30 jaar stemacteur en weet als geen ander zijn eigen stem te gebruiken én andere stemmen na te doen.
Hoe klinkt een stem?
Hoe mensen precies geluid maken met hun stem is vrij ingewikkeld, maar het principe is simpel. Je ademt lucht uit, tijdens het uitademen komt de lucht langs de stembanden die trillen en voilà, je hebt geluid! Geluid is immers niet meer dan trillende lucht. De grootte en vorm van je spraakkanaal — en ook de rest van je lichaam — bepalen hoe je stem klinkt. Hier heb je zelf ook nog invloed op, met het aanspannen (of ontspannen) van spieren kun je de klank aanpassen.
Aan de vorm van je lichaam kun je niet veel veranderen, maar (met wat oefening) wel hoe je de lucht door je spraakkanaal stuurt. Dit is precies wat Boet doet om een stem na te doen:
“Je hebt een klankkast, en die klankkast bestaat uit een aantal echokamers: je longen, je keel, je neus en je strot. Als je kunt beslissen waar de lucht heengaat dan kun je ontzettend veel met je stem doen”.
Neem het voorbeeld van de stemmen van Morgan Freeman en Michael Cane, die Boet beiden goed na kan doen. Voor Morgan Freeman stuur je de meeste lucht door de neus, voor Michael Cane juist door de keel. Er zijn natuurlijk wel beperkingen aan hoe ver je kunt gaan met je eigen stem. Boet heeft een vrij lage stem: “Bij mij is dat laag zo aanwezig, dat ik heel gemakkelijk dat lage geluid krijg aan het eind van de zin zoals bij Morgan Freeman. Dat betekent dat je sommige stemmen minder goed kunt nadoen dan anderen. Ik heb gewoon een bepaald timbre waar ik in gespecialiseerd ben.”
Het klankgedeelte van een stem is voor een computer een stuk minder ingewikkeld, in theorie zijn de mogelijkheden oneindig. Een computer heeft namelijk geen uniek spraakkanaal of lichaam nodig, maar een speaker. Met een speaker kan een veel groter bereik aan tonen worden geproduceerd dan met het menselijk spraakkanaal.
Wat zegt de stem?
Dat wil echter niet zeggen dat het voor een computer veel makkelijker is om een stem te produceren, want klank is niet het enige aspect van een stem. Voordat je klanken kunt maken moet je eerst weten wélke klanken je wilt maken. Voor mensen gaat dat natuurlijk, taal is onze voornaamste manier van communicatie. De ontwikkeling van taal begint dan ook vroeg, baby’s leren al vóór de geboorte de stem van hun moeder te herkennen [1].
Met de komst van machine learning is er een grote vooruitgang gemaakt in het leren van taal aan computers. Mensen hebben echter duidelijk nog wel een voorsprong. Op jonge leeftijd verhuisde Boet met zijn gezin naar Afrika. Daar groeide hij op tussen mensen van allerlei verschillende nationaliteiten. “Van jongs af aan vond ik het leuk, ik kon ook best veel stemmetjes doen toen ik klein was. Het viel wel op dat mijn Engels heel goed was en dat ik mensen die volwassenen waren kon verbeteren in hun Engels. Als ik één keer een woord uitgesproken hoorde worden, dan zat het meteen in mijn hersenen opgeslagen als de goede uitspraak”, herinnert hij zich. Met machine learning kan een computer ook leren ‘begrijpen’ wat de goede uitspraak is, het heeft alleen veel meer dan één voorbeeld nodig om dit te kunnen doen.
Hoe praat de stem?
Naast deze twee belangrijke onderdelen, klank en taal, is er nog een derde element dat een stem echt eigen maakt. Iedereen heeft een eigen specifieke manier van praten. Om deze manier van praten na te doen moet je dus goed kunnen horen welke onderdelen een stem karakteristiek maken. Wie daar volgens Boet ook erg goed in is, is Edwin Evers. Edwin Evers doet een overtuigende imitatie van de broertjes De Boer die je ongetwijfeld wel eens gehoord hebt. Boet zegt: “Hij overdreef dus heel erg die specifieke onderdelen van de stem die het echt apart maakten.” Het uitvergroten van specifieke elementen uit de stemmen gaf andere mensen ook aanleiding om eens een imitatie te proberen.
“Je had op een gegeven moment Johan Cruijffs en een heleboel Frank en Ronald de Boers die je regelmatig te horen kreeg.”
Een computer kun je min of meer hetzelfde proces aanleren. Door een stem van een specifiek persoon te vergelijken met het gemiddelde van een groot aantal stemmen is er een karakteristiek te destilleren; dit noemt men een embedding [2] (waarover later meer).
Voor een mens is het makkelijk om een karakteristiek te registreren, of een beeld te vormen. Boet maakt een treffende vergelijking: “Als je kijkt naar een scherm en daar staan een paar miljoen pixels op, dan zie je die pixels niet, maar je ziet een beeld. En dat beeld roept herinneringen op of emoties. Een computer ziet gewoon allemaal pixels.” Met machine learning komt daar dus verandering in. Door de computer vele verschillende stemmen te laten ‘horen’, kan het deze leren ‘begrijpen’.
Een grafische weergave van een embedding van mijn eigen stem
Om een stem na te doen heb je dus de nodige kennis van taal nodig, een goed gehoor voor klank én de fysieke vaardigheid om deze na te doen. Al met al zijn er misschien wel 100 verschillende onderdeeltjes die een stem specifiek maken volgens Boet. “Je hersenen zijn iets heel moois, die kunnen dat registreren, opslaan en vervolgens zonder erbij na te denken wordt dat allemaal automatisch uitgevoerd.”
Tijd voor audio deepfakes!
Met kennis van deze basisonderdelen kunnen we kijken naar hoe de meeste AI stemmen worden opgebouwd. In 2018 publiceerden enkele medewerkers van Google een paper genaamd “Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis” [2]. Interessante theorie, maar hoe krijg ik hier een kant en klare stem uit? In 2019 werd er een open source implementatie van gemaakt van het paper in programmeertaal Python: Real-Time Voice Cloning [3]. Het paper beschrijft een nieuwe techniek, Speech Vector to Text-To-Speech, ofwel SV2TTS. Met deze techniek kun je met een paar seconden aan referentieaudio van een stem compleet nieuwe audio genereren met dezelfde stem, met als input tekst. Je geeft de computer dus audio van een stem, voert tekst in, en een paar seconden later heb je een gesynthetiseerde stem die jouw tekst uitspreekt.
Het SV2TTS model bestaat uit drie onderdelen. Om deze onderdelen te begrijpen is het handig om te weten wat een mel spectrogram is.
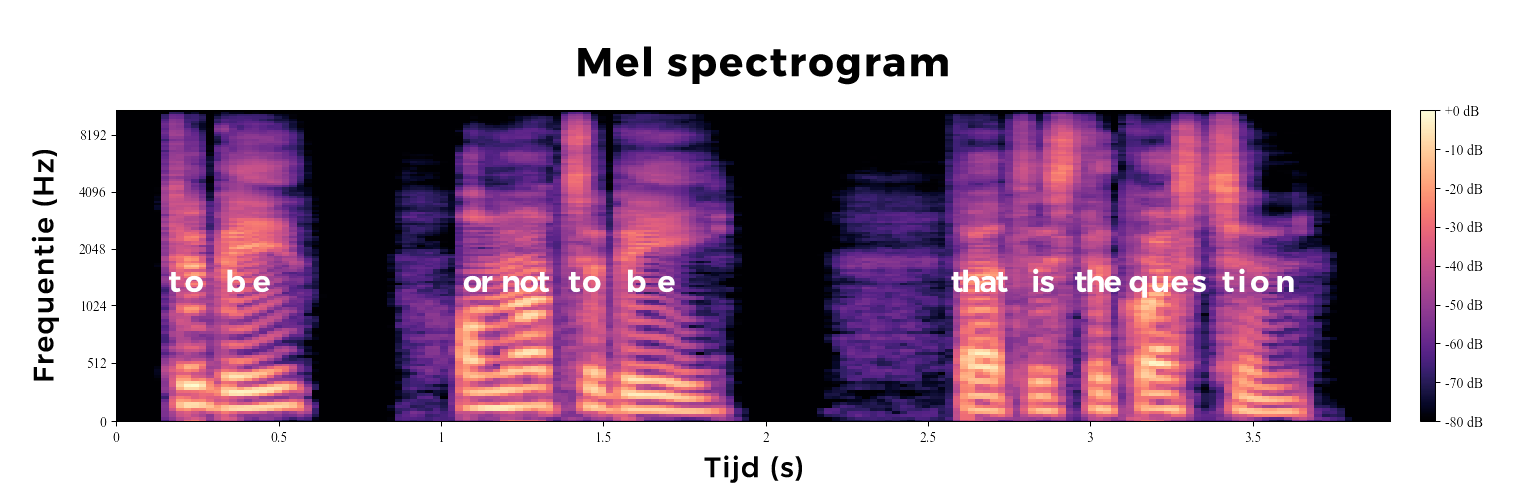
Een mel spectrogram van mijn stem (met de woorden die ik uitspreek toegevoegd)
Een spectrogram is een manier om het spectrum van frequenties in audio te visueel te weergeven. In een mel spectrogram worden de frequenties weergeven op de mel schaal, een soort logaritmische schaal waarbij de afstanden tussen frequenties overeenkomen met hoe die door het menselijk oor worden waargenomen.
Speech Vector to Text-To-Speech
De drie onderdelen van het SV2TTS model werken als volgt:
- De speaker encoder zorgt ervoor dat de stem uit de referentieaudio vertaald wordt naar een embedding. Deze embedding is een manier om de karakteristieken van een stem op te slaan in een reeks getallen (de technische term hiervoor is een low dimensional vector). Als we dat vergelijken met het proces van Boet, in de speaker encoder zit dus zowel het begrip voor taal als het begrijpen van welke onderdelen een stem karakteristiek maakt.
- De synthesizer vertaalt de inputtekst naar een mel spectrogram aan de hand van de embedding. De synthesizer deelt de tekst op in fonemen, de klanken die een stem maakt bij het uitspreken van de letters. Vervolgens genereert het een nieuw spectrogram met als referentie de embedding van de referentieaudio. Nu hebben we een mel spectrogram, dus een plaatje, maar nog geen audio.
- De vocoder maakt de laatste vertaalslag, van spectrogram naar audio. De vocoder is gebaseerd op WaveNet, een deep neural network dat bij Google ontwikkeld werd om audio te genereren [4].
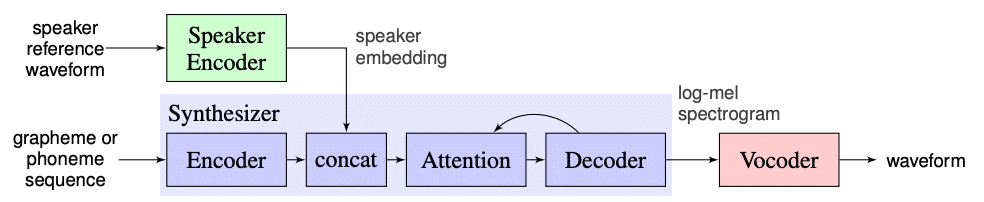
Kort gezegd: de speaker encoder slaat de karakteristieken van een stem op, de synthesizer vertaalt tekst naar de bouwstenen van spraak, tot slot zet de vocoder deze data om in audio.
Deze drie modellen zijn neural networks, ze moeten dus elk afzonderlijk getraind worden op bestaande data. Train je bijvoorbeeld de synthesizer niet, dan kan de vocoder wel spraak genereren maar moet het gokken wát het moet zeggen.
Ook mensen moeten getraind worden, het gebeurt alleen een stuk natuurlijker merkt Boet op: “Dat is het mooie van als je iets doet waar je lolt in hebt. Talent hebben betekent ook dat je in principe niet doorhebt dat je jezelf aan het trainen bent.” Voor zijn werk als stemacteur komt hij vaak in geluidsstudio’s, de ideale plek om zijn imitaties uit te proberen voor publiek met een getraind oor. “De geluidstechnici hoorde meteen wat er nog niet goed was aan die stem, en dat nam ik dan in me op en dan ging ik een beetje meer oefenen.”
Met Real-Time Voice Cloning zijn modellen te downloaden die al getraind zijn. Dat is fijn, want dat scheelt een hele hoop tijd (in dit geval heeft het ongeveer een maand gekost om alle modellen te trainen). Er kan zo 300 tot 500 uur aan audio nodig zijn om een goed resultaat te krijgen. Omdat deze modellen zijn getraind op Engelse audioboeken is het met deze implementatie alleen mogelijk om stemmen in het Engels te klonen.
To be, or not to be?
Deze implementatie van SV2TTS is vrij experimenteel en zeker niet perfect. De modellen zijn getraind op tekst zonder interpunctie, wat soms voor problemen zorgt. Één van mijn pogingen om mijn AI alter ego een stukje Shakespeare te laten voordragen resulteerde in de volgende audio.
Dit framework is interessant om te experimenteren met de techniek, maar voor serieuze toepassingen is het niet bruikbaar. De makers hebben hun implementatie echter verder uitgewerkt tot een commerciële dienst die Resemble heet. Bij Resemble is het mogelijk om op gebruiksvriendelijke wijze — zonder zelf te hoeven programmeren — stemmen te klonen. Alle modellen zijn door Resemble getraind, het enige dat je zelf nog hoeft te doen is het inspreken van een aantal referentiezinnen. Het is al mogelijk om met vijf minuten aan gesproken audio een degelijk resultaat te krijgen. Onderstaande fragment is een kloon van mijn eigen stem, gemaakt met de gratis versie van Resemble.
Het is onwaarschijnlijk dat iemand gelooft dat hier een echt persoon aan het woord is, maar mijn stem is zeker te herkennen en zo nu en dan voelt het toch behoorlijk menselijk aan.
Een andere commerciële dienst die met dezelfde techniek werkt is Overdub van Descript. Met het inspreken van ongeveer 45 minuten aan referentieaudio kreeg ik een behoorlijk goed resultaat!
Mijn AI stem die de “We choose to go to the moon” speech van Amerikaanse president John F. Kennedy houdt.
Mijn AI stem die de stem van Scarlett Johansson vervangt als AI assistent in de film HER.
Zeker als je de gegenereerde stem in een context plaatst begint het resultaat steeds realistischer te worden. Dit is tegelijkertijd ook waar het gevaar van audio deepfakes ontstaat. Stel je voor dat je deze stem in een luidruchtige context hoort — bijvoorbeeld door een telefoon op een drukke plek — en het wordt al een stuk minder duidelijk dat er geen echt persoon aan de lijn is.
De toekomst van audio deepfakes
Het klonen en synthetiseren van nieuwe stemmen wordt met de dag makkelijker én geloofwaardiger. Het is nog niet perfect, maar ook ervaren stemacteur Boet was onder de indruk toen hij voor het eerst de nieuwe AI stem van Google Maps hoorde: “Maar ik hoor ook wat ze getweakt hebben. Het lijkt nog lang niet op wat een goede stem kan doen.” De emotie, pauzes en interpretatie van de tekst zijn gebieden waarop mensen voorlopig nog beter zullen presteren dan computers. Voor sommige toepassingen zullen menselijke stemmen waarschijnlijk altijd het beste resultaat geven.
Er zijn echter wel een hoop andere toepassingen van AI stemmen denkbaar, zowel hele interessante als gevaarlijke. Hierover volgende keer meer, in het laatste deel van deze reeks!
[1] Hepper, P. G., Scott, D. & Shahidullah, S. Newborn and fetal response to maternal voice. (1992)
[2] Jia, Y., Zhang, Yu & Weiss, R. Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis. (2018)
[3] Corentin, J. Real-Time Voice Cloning. (2019)
[4] van den Oord, A & Dieleman, S. WaveNet: A Generative Model For Raw Audio. (2016)
Met dank aan Boet Schouwink.