


Liever luisteren dan lezen? Dit artikel is ook beschikbaar in gesproken variant:
![]()
![]()
![]()
![]()
![]()
Deel 1: Welcome to the machine
Dezelfde techniek is niet alleen op beeld toe te passen, maar ook op audio. Met deep learning is het mogelijk om de karakteristieken van een stem te ‘klonen’ en daarmee vervolgens nieuwe tekst uit te spreken. Bij een deepfake gaat het om het kopieëren van een bestaande stem. Maar voordat je een bestaande stem na kunt bootsen moet je een computer eerst zien te leren hoe hij überhaupt kan spreken. We spreken hier over spraaksynthese: het kunstmatig samenstellen van spraak (door bijvoorbeeld een mechanische machine, of een computer).
Mensen proberen al bijna 250 jaar spraak na te bootsen op allerlei verschillende manieren. Tegenwoordig kunnen we dat doen met AI (kunstmatige intelligentie), maar ook vóór het ontstaan van de computer zijn er pogingen geweest. Hoe werkt deze technologie precies? Waar komt het vandaan? Wat kun je er mee en hoe ziet de toekomst van AI stemmen eruit? Daarover gaan we in deze serie op onderzoek uit én ga ik aan de slag met het klonen van mijn eigen stem!
Om te begrijpen hoe je een stem kunt synthetiseren duiken we in de wereld van kunstmatige intelligentie. Binnen kunstmatige intelligentie is er een onderzoeksveld dat machine learning heet. Machine learning houdt in dat een model getraind wordt op bepaalde data met behulp van een algoritme, om daar vervolgens van te leren hoe het zelf data dat het nog niet kent kan verwerken. Simpel gezegd, met machine learning leer je een computer om zelf te bedenken hoe en wat hij moet doen met data (binnen bepaalde grenzen).
Deep learning
Er zijn vele verschillende vormen van machine learning. Een van deze vormen is deep learning. Deze manier wordt gebruikt voor het synthetiseren van stemmen én dus ook het maken van deepfakes. Deep learning is overigens ook de techniek die zelfrijdende auto’s, de spraakherkenning in je telefoon, het personaliseren van advertenties op social media en een hoop medische vooruitgang mogelijk maakt. Deep learning maakt gebruik van artificial neural networks, meestal simpelweg neural networks genoemd. Een neural network is een serie van algoritmes, of lagen, dat als doel heeft onderlinge relaties te herkennen in data. Dit doen ze met een proces dat is afgekeken van de werkwijze van het menselijk brein. Het woord ‘deep’ uit deep learning duidt op het aantal lagen in deze netwerken, dat bij deep learning ver op kan lopen.
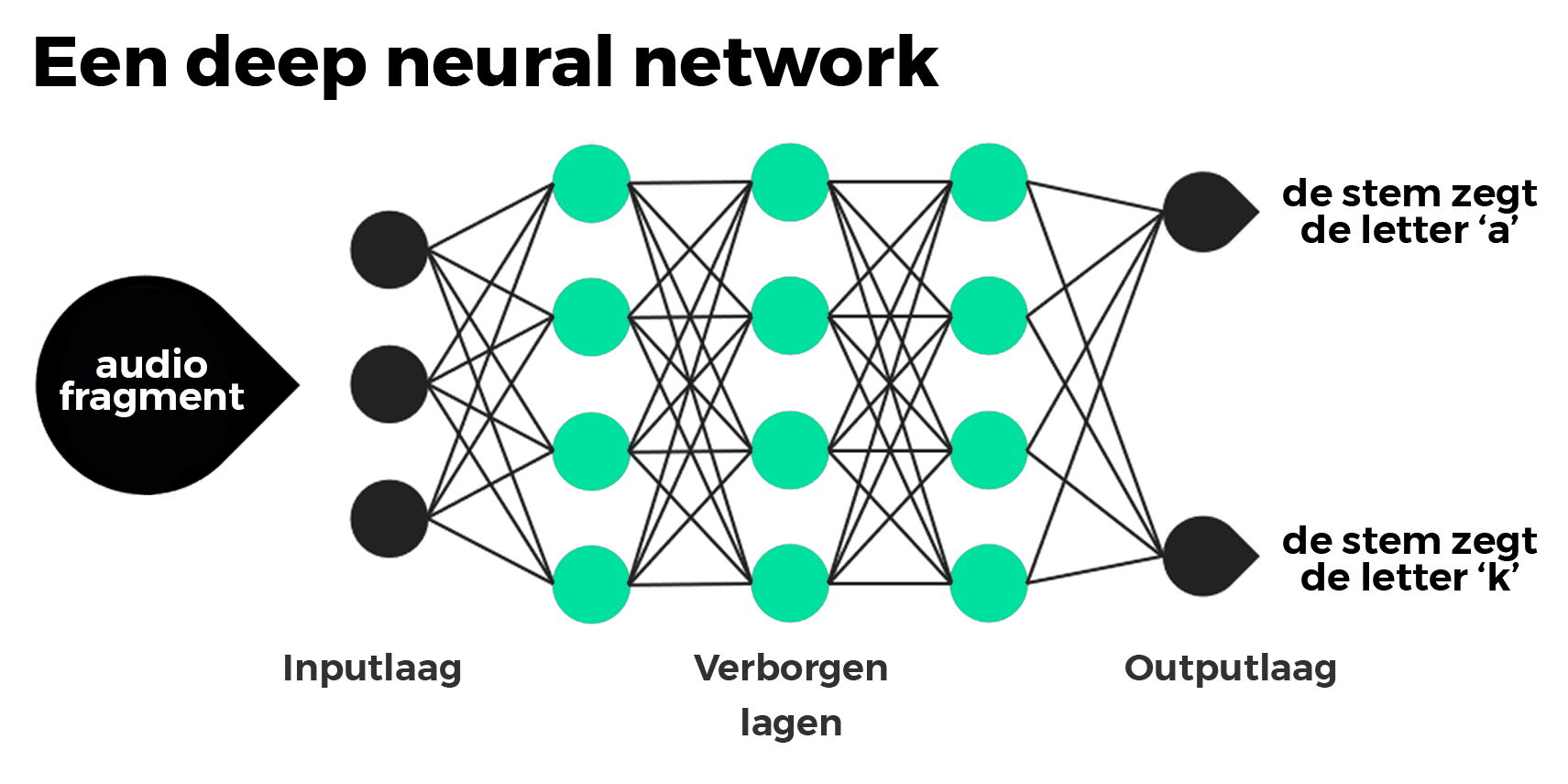
Een versimpelde weergave van de structuur van een deep neural network voor bijvoorbeeld spraakherkenning
De eerste theorieën voor deep learning ontstonden in de jaren ’80, maar pas sinds relatief korte tijd zijn deze uitvoerbaar en populair. De redenen hiervoor zijn dat deep learning ten eerste heel veel gelabelde data nodig heeft om een model te kunnen trainen. Voor het ontwikkelen van spraakherkenning zijn er bijvoorbeeld honderden uren aan audio nodig van spraak, met de daarbij behorende tekst. Tegenwoordig is een harde schijf van een paar terabyte prima te betalen, maar in de jaren ’80 was dat een heel ander verhaal. Daarnaast is er voor deep learning aanzienlijke rekenkracht nodig. Met name GPU’s (grafische processors) zijn geschikt voor deep learning vanwege hun efficiëntie in het uitvoeren van parallelle processen. De ontwikkeling van deze GPU’s is pas in recente jaren ver genoeg om op grote schaal serieus met deep learning aan de slag te kunnen.
Wolfgang von Kempelen’s spraakmachine & de eerste elektrische spraaksynthesizer
Dat wil echter niet zeggen dat mensen niet al langer bezig zijn met het synthetiseren van spraak. In 1769 ontwikkelde de Oostenrijks-Hongaarse Wolfgang von Kempelen een met de hand bediende spraakmachine [1].
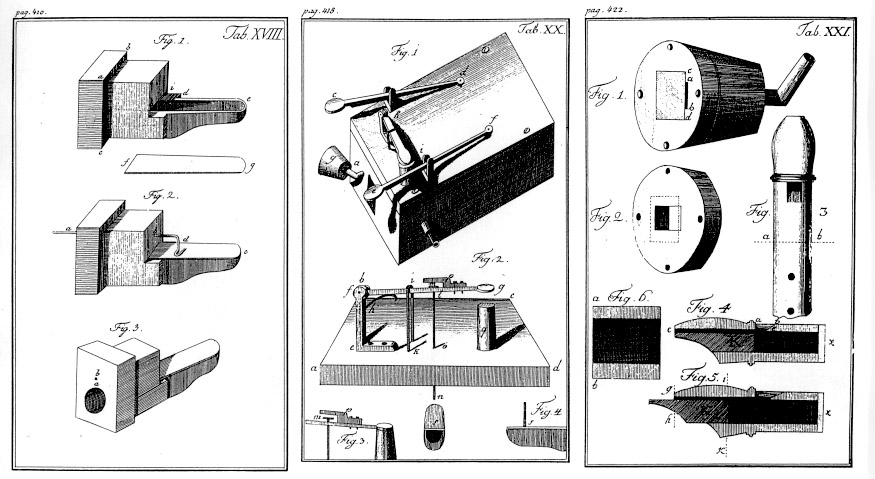
In zijn ontwerp bootste hij mechanisch het menselijke spraakkanaal na om zo spraak-achtige klanken te produceren. Natuurlijkheid en verstaanbaarheid zijn nog ver te zoeken, maar het begin is gemaakt!
De eerste elektrische spraaksynthesizer — de VODER — werd in 1939 gepresenteerd op de New York World’s Fair. De VODER werkte op basis van een gegenereerd signaal dat met filters werd bewerkt om als een stem te laten klinken. Het bedienen van de machine ging met een voetpedaal en toetsenbord dat met tien vingers bediend moest worden, niet bepaald de meest gebruiksvriendelijke synthesizer.
Een andere bekende spraaksynthesizer aan het begin van deze ontwikkeling is de IBM 704 computer die het liedje ‘Daisy Bell’ zingt, in 1961. Voor de Stanley Kubrick fans: dit is hetzelfde liedje dat computer HAL 9000 zingt aan het eind van 2001: A Space Odyssee.
Waar de voorgaande systemen nog met de hand werden geprogrammeerd of bediend was de volgende ontwikkeling een text-to-speech systeem. In 1968 ontwikkelde Noriko Umeda met zijn team in Japan zo’n systeem, dat enkel tekst als input nodig had [2].
En toen…
Vanaf de jaren ’70 komen er steeds meer commerciële text-to-speech producten op de markt, veelal in draagbare apparaten als rekenmachines. In de jaren ’80 komen daar ook nog computerspelletjes bij.
Al deze pogingen tot het nabootsen van spraak gebruikten verschillende vormen van synthese. Sommigen waren uitgebreide versies van het simpelweg samenvoegen van verschillende stukjes uit spraakopnames. Anderen waren weer ingewikkeldere vormen van het samenvoegen van tonen en ruis. Pas in de laatste tien jaar is het gebruik van neural networks toegepast in spraaksynthese. Daarmee zijn de twee belangrijkste kwaliteiten van spraaksynthese, natuurlijkheid en verstaanbaarheid, razendsnel verbeterd.
Hoe haalbaar is het om zelf je stem te klonen met AI? En hoe doe je dat? Daarover volgende keer meer!
[1] von Kempelen, Wolfgang. Mechanismus der menschlichen Sprache. Wien (1791)
[2] Umeda, N. & R. Teranishi. The parsing program for
automatic text-to-speech synthesis developed at the Electro-
technical Laboratory in 1968. (1968)